joblib.Parallel¶
- class joblib.Parallel(n_jobs=default(None), backend=default(None), return_as='list', verbose=default(0), timeout=None, pre_dispatch='2 * n_jobs', batch_size='auto', temp_folder=default(None), max_nbytes=default('1M'), mmap_mode=default('r'), prefer=default(None), require=default(None), **backend_kwargs)¶
Helper class for readable parallel mapping.
Read more in the User Guide.
- Parameters:
- n_jobs: int, default=None
The maximum number of concurrently running jobs, such as the number of Python worker processes when
backend="loky"or the size of the thread-pool whenbackend="threading". This argument is converted to an integer, rounded below for float. If -1 is given, joblib tries to use all CPUs. The number of CPUsn_cpusis obtained withcpu_count(). For n_jobs below -1, (n_cpus + 1 + n_jobs) are used. For instance, usingn_jobs=-2will result in all CPUs but one being used. This argument can also go aboven_cpus, which will cause oversubscription. In some cases, slight oversubscription can be beneficial, e.g., for tasks with large I/O operations. If 1 is given, no parallel computing code is used at all, and the behavior amounts to a simple python for loop. This mode is not compatible withtimeout. None is a marker for ‘unset’ that will be interpreted as n_jobs=1 unless the call is performed under aparallel_config()context manager that sets another value forn_jobs. If n_jobs = 0 then a ValueError is raised.- backend: str, ParallelBackendBase instance or None, default=’loky’
Specify the parallelization backend implementation. Supported backends are:
“loky” used by default, can induce some communication and memory overhead when exchanging input and output data with the worker Python processes. On some rare systems (such as Pyiodide), the loky backend may not be available.
“multiprocessing” previous process-based backend based on multiprocessing.Pool. Less robust than loky.
“threading” is a very low-overhead backend but it suffers from the Python Global Interpreter Lock if the called function relies a lot on Python objects. “threading” is mostly useful when the execution bottleneck is a compiled extension that explicitly releases the GIL (for instance a Cython loop wrapped in a “with nogil” block or an expensive call to a library such as NumPy).
finally, you can register backends by calling
register_parallel_backend(). This will allow you to implement a backend of your liking.
It is not recommended to hard-code the backend name in a call to
Parallelin a library. Instead it is recommended to set soft hints (prefer) or hard constraints (require) so as to make it possible for library users to change the backend from the outside using theparallel_config()context manager.- return_as: str in {‘list’, ‘generator’, ‘generator_unordered’}, default=’list’
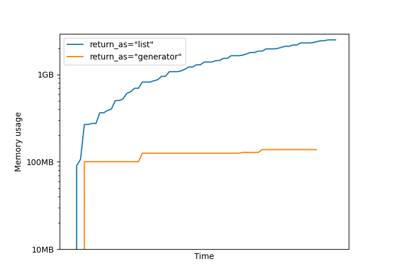
If ‘list’, calls to this instance will return a list, only when all results have been processed and retrieved. If ‘generator’, it will return a generator that yields the results as soon as they are available, in the order the tasks have been submitted with. If ‘generator_unordered’, the generator will immediately yield available results independently of the submission order. The output order is not deterministic in this case because it depends on the concurrency of the workers.
- prefer: str in {‘processes’, ‘threads’} or None, default=None
Soft hint to choose the default backend if no specific backend was selected with the
parallel_config()context manager. The default process-based backend is ‘loky’ and the default thread-based backend is ‘threading’. Ignored if thebackendparameter is specified.- require: ‘sharedmem’ or None, default=None
Hard constraint to select the backend. If set to ‘sharedmem’, the selected backend will be single-host and thread-based even if the user asked for a non-thread based backend with
parallel_config().- verbose: int, default=0
The verbosity level: if non zero, progress messages are printed. Above 50, the output is sent to stdout. The frequency of the messages increases with the verbosity level. If it more than 10, all iterations are reported.
- timeout: float or None, default=None
Timeout limit for each task to complete. If any task takes longer a TimeOutError will be raised. Only applied when n_jobs != 1
- pre_dispatch: {‘all’, integer, or expression, as in ‘3*n_jobs’}, default=’2*n_jobs’
The number of batches (of tasks) to be pre-dispatched. Default is ‘2*n_jobs’. When batch_size=”auto” this is reasonable default and the workers should never starve. Note that only basic arithmetic are allowed here and no modules can be used in this expression.
- batch_size: int or ‘auto’, default=’auto’
The number of atomic tasks to dispatch at once to each worker. When individual evaluations are very fast, dispatching calls to workers can be slower than sequential computation because of the overhead. Batching fast computations together can mitigate this. The
'auto'strategy keeps track of the time it takes for a batch to complete, and dynamically adjusts the batch size to keep the time on the order of half a second, using a heuristic. The initial batch size is 1.batch_size="auto"withbackend="threading"will dispatch batches of a single task at a time as the threading backend has very little overhead and using larger batch size has not proved to bring any gain in that case.- temp_folder: str or None, default=None
Folder to be used by the pool for memmapping large arrays for sharing memory with worker processes. If None, this will try in order:
a folder pointed by the JOBLIB_TEMP_FOLDER environment variable,
/dev/shm if the folder exists and is writable: this is a RAM disk filesystem available by default on modern Linux distributions,
the default system temporary folder that can be overridden with TMP, TMPDIR or TEMP environment variables, typically /tmp under Unix operating systems.
Only active when
backend="loky"or"multiprocessing".- max_nbytes int, str, or None, optional, default=’1M’
Threshold on the size of arrays passed to the workers that triggers automated memory mapping in temp_folder. Can be an int in Bytes, or a human-readable string, e.g., ‘1M’ for 1 megabyte. Use None to disable memmapping of large arrays. Only active when
backend="loky"or"multiprocessing".- mmap_mode: {None, ‘r+’, ‘r’, ‘w+’, ‘c’}, default=’r’
Memmapping mode for numpy arrays passed to workers. None will disable memmapping, other modes defined in the numpy.memmap doc: https://numpy.org/doc/stable/reference/generated/numpy.memmap.html Also, see ‘max_nbytes’ parameter documentation for more details.
- backend_kwargs: dict, optional
Additional parameters to pass to the backend configure method.
Notes
This object uses workers to compute in parallel the application of a function to many different arguments. The main functionality it brings in addition to using the raw multiprocessing or concurrent.futures API are (see examples for details):
More readable code, in particular since it avoids constructing list of arguments.
- Easier debugging:
informative tracebacks even when the error happens on the client side
using ‘n_jobs=1’ enables to turn off parallel computing for debugging without changing the codepath
early capture of pickling errors
An optional progress meter.
Interruption of multiprocesses jobs with ‘Ctrl-C’
Flexible pickling control for the communication to and from the worker processes.
Ability to use shared memory efficiently with worker processes for large numpy-based datastructures.
Note that the intended usage is to run one call at a time. Multiple calls to the same Parallel object will result in a
RuntimeErrorExamples
A simple example:
>>> from math import sqrt >>> from joblib import Parallel, delayed >>> Parallel(n_jobs=1)(delayed(sqrt)(i**2) for i in range(10)) [0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]
Reshaping the output when the function has several return values:
>>> from math import modf >>> from joblib import Parallel, delayed >>> r = Parallel(n_jobs=1)(delayed(modf)(i/2.) for i in range(10)) >>> res, i = zip(*r) >>> res (0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5) >>> i (0.0, 0.0, 1.0, 1.0, 2.0, 2.0, 3.0, 3.0, 4.0, 4.0)
The progress meter: the higher the value of verbose, the more messages:
>>> from time import sleep >>> from joblib import Parallel, delayed >>> r = Parallel(n_jobs=2, verbose=10)( ... delayed(sleep)(.2) for _ in range(10)) [Parallel(n_jobs=2)]: Done 1 tasks | elapsed: 0.6s [Parallel(n_jobs=2)]: Done 4 tasks | elapsed: 0.8s [Parallel(n_jobs=2)]: Done 10 out of 10 | elapsed: 1.4s finished
Traceback example, note how the line of the error is indicated as well as the values of the parameter passed to the function that triggered the exception, even though the traceback happens in the child process:
>>> from heapq import nlargest >>> from joblib import Parallel, delayed >>> Parallel(n_jobs=2)( ... delayed(nlargest)(2, n) for n in (range(4), 'abcde', 3)) ... ----------------------------------------------------------------------- Sub-process traceback: ----------------------------------------------------------------------- TypeError Mon Nov 12 11:37:46 2012 PID: 12934 Python 2.7.3: /usr/bin/python ........................................................................ /usr/lib/python2.7/heapq.pyc in nlargest(n=2, iterable=3, key=None) 419 if n >= size: 420 return sorted(iterable, key=key, reverse=True)[:n] 421 422 # When key is none, use simpler decoration 423 if key is None: --> 424 it = izip(iterable, count(0,-1)) # decorate 425 result = _nlargest(n, it) 426 return map(itemgetter(0), result) # undecorate 427 428 # General case, slowest method TypeError: izip argument #1 must support iteration _______________________________________________________________________
Using pre_dispatch in a producer/consumer situation, where the data is generated on the fly. Note how the producer is first called 3 times before the parallel loop is initiated, and then called to generate new data on the fly:
>>> from math import sqrt >>> from joblib import Parallel, delayed >>> def producer(): ... for i in range(6): ... print('Produced %s' % i) ... yield i >>> out = Parallel(n_jobs=2, verbose=100, pre_dispatch='1.5*n_jobs')( ... delayed(sqrt)(i) for i in producer()) Produced 0 Produced 1 Produced 2 [Parallel(n_jobs=2)]: Done 1 jobs | elapsed: 0.0s Produced 3 [Parallel(n_jobs=2)]: Done 2 jobs | elapsed: 0.0s Produced 4 [Parallel(n_jobs=2)]: Done 3 jobs | elapsed: 0.0s Produced 5 [Parallel(n_jobs=2)]: Done 4 jobs | elapsed: 0.0s [Parallel(n_jobs=2)]: Done 6 out of 6 | elapsed: 0.0s remaining: 0.0s [Parallel(n_jobs=2)]: Done 6 out of 6 | elapsed: 0.0s finished
- dispatch_next()¶
Dispatch more data for parallel processing
This method is meant to be called concurrently by the multiprocessing callback. We rely on the thread-safety of dispatch_one_batch to protect against concurrent consumption of the unprotected iterator.
- dispatch_one_batch(iterator)¶
Prefetch the tasks for the next batch and dispatch them.
The effective size of the batch is computed here. If there are no more jobs to dispatch, return False, else return True.
The iterator consumption and dispatching is protected by the same lock so calling this function should be thread safe.
- print_progress()¶
Display the process of the parallel execution only a fraction of time, controlled by self.verbose.
Examples using joblib.Parallel¶

Checkpoint using joblib.Memory and joblib.Parallel