Note
Go to the end to download the full example code.
Improving I/O using compressors#
This example compares the compressors available in Joblib. In the example, Zlib, LZMA and LZ4 compression only are used but Joblib also supports BZ2 and GZip compression methods. For each compared compression method, this example dumps and reloads a dataset fetched from an online machine-learning database. This gives 3 information: the size on disk of the compressed data, the time spent to dump and the time spent to reload the data from disk.
import os
import os.path
import time
Get some data from real-world use cases#
First fetch the benchmark dataset from an online machine-learning database and load it in a pandas dataframe.
import pandas as pd
url = "https://github.com/joblib/dataset/raw/main/kddcup.data.gz"
names = (
"duration, protocol_type, service, flag, src_bytes, "
"dst_bytes, land, wrong_fragment, urgent, hot, "
"num_failed_logins, logged_in, num_compromised, "
"root_shell, su_attempted, num_root, "
"num_file_creations, "
).split(", ")
data = pd.read_csv(url, names=names, nrows=1e6)
Dump and load the dataset without compression#
This gives reference values for later comparison.
from joblib import dump, load
pickle_file = "./pickle_data.joblib"
Start by measuring the time spent for dumping the raw data:
start = time.time()
with open(pickle_file, "wb") as f:
dump(data, f)
raw_dump_duration = time.time() - start
print("Raw dump duration: %0.3fs" % raw_dump_duration)
Raw dump duration: 0.060s
Then measure the size of the raw dumped data on disk:
raw_file_size = os.stat(pickle_file).st_size / 1e6
print("Raw dump file size: %0.3fMB" % raw_file_size)
Raw dump file size: 167.219MB
Finally measure the time spent for loading the raw data:
start = time.time()
with open(pickle_file, "rb") as f:
load(f)
raw_load_duration = time.time() - start
print("Raw load duration: %0.3fs" % raw_load_duration)
Raw load duration: 0.345s
Dump and load the dataset using the Zlib compression method#
The compression level is using the default value, 3, which is, in general, a good compromise between compression and speed.
Start by measuring the time spent for dumping of the zlib data:
start = time.time()
with open(pickle_file, "wb") as f:
dump(data, f, compress="zlib")
zlib_dump_duration = time.time() - start
print("Zlib dump duration: %0.3fs" % zlib_dump_duration)
Zlib dump duration: 0.382s
Then measure the size of the zlib dump data on disk:
zlib_file_size = os.stat(pickle_file).st_size / 1e6
print("Zlib file size: %0.3fMB" % zlib_file_size)
Zlib file size: 3.947MB
Finally measure the time spent for loading the compressed dataset:
start = time.time()
with open(pickle_file, "rb") as f:
load(f)
zlib_load_duration = time.time() - start
print("Zlib load duration: %0.3fs" % zlib_load_duration)
Zlib load duration: 0.439s
Note
The compression format is detected automatically by Joblib. The compression format is identified by the standard magic number present at the beginning of the file. Joblib uses this information to determine the compression method used. This is the case for all compression methods supported by Joblib.
Dump and load the dataset using the LZMA compression method#
LZMA compression method has a very good compression rate but at the cost of being very slow. In this example, a light compression level, e.g. 3, is used to speed up a bit the dump/load cycle.
Start by measuring the time spent for dumping the lzma data:
start = time.time()
with open(pickle_file, "wb") as f:
dump(data, f, compress=("lzma", 3))
lzma_dump_duration = time.time() - start
print("LZMA dump duration: %0.3fs" % lzma_dump_duration)
LZMA dump duration: 1.355s
Then measure the size of the lzma dump data on disk:
lzma_file_size = os.stat(pickle_file).st_size / 1e6
print("LZMA file size: %0.3fMB" % lzma_file_size)
LZMA file size: 2.117MB
Finally measure the time spent for loading the lzma data:
start = time.time()
with open(pickle_file, "rb") as f:
load(f)
lzma_load_duration = time.time() - start
print("LZMA load duration: %0.3fs" % lzma_load_duration)
LZMA load duration: 0.504s
Dump and load the dataset using the LZ4 compression method#
LZ4 compression method is known to be one of the fastest available compression method but with a compression rate a bit lower than Zlib. In most of the cases, this method is a good choice.
Note
In order to use LZ4 compression with Joblib, the lz4 package must be installed on the system.
Start by measuring the time spent for dumping the lz4 data:
start = time.time()
with open(pickle_file, "wb") as f:
dump(data, f, compress="lz4")
lz4_dump_duration = time.time() - start
print("LZ4 dump duration: %0.3fs" % lz4_dump_duration)
LZ4 dump duration: 0.062s
Then measure the size of the lz4 dump data on disk:
lz4_file_size = os.stat(pickle_file).st_size / 1e6
print("LZ4 file size: %0.3fMB" % lz4_file_size)
LZ4 file size: 6.259MB
Finally measure the time spent for loading the lz4 data:
start = time.time()
with open(pickle_file, "rb") as f:
load(f)
lz4_load_duration = time.time() - start
print("LZ4 load duration: %0.3fs" % lz4_load_duration)
LZ4 load duration: 0.363s
Comparing the results#
import matplotlib.pyplot as plt
import numpy as np
N = 4
load_durations = (
raw_load_duration,
lz4_load_duration,
zlib_load_duration,
lzma_load_duration,
)
dump_durations = (
raw_dump_duration,
lz4_dump_duration,
zlib_dump_duration,
lzma_dump_duration,
)
file_sizes = (raw_file_size, lz4_file_size, zlib_file_size, lzma_file_size)
ind = np.arange(N)
width = 0.5
plt.figure(1, figsize=(5, 4))
p1 = plt.bar(ind, dump_durations, width)
p2 = plt.bar(ind, load_durations, width, bottom=dump_durations)
plt.ylabel("Time in seconds")
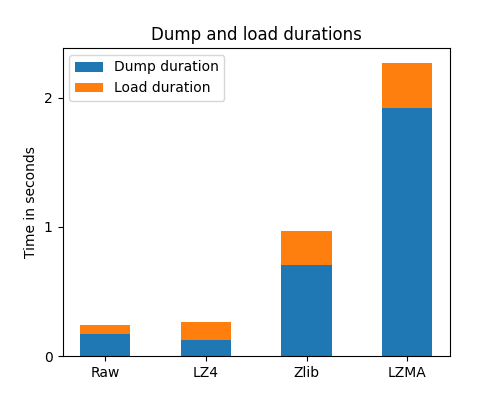
plt.title("Dump and load durations")
plt.xticks(ind, ("Raw", "LZ4", "Zlib", "LZMA"))
plt.yticks(np.arange(0, lzma_load_duration + lzma_dump_duration))
plt.legend((p1[0], p2[0]), ("Dump duration", "Load duration"))
<matplotlib.legend.Legend object at 0x7502f7f9d400>
Compared with other compressors, LZ4 is clearly the fastest, especially for dumping compressed data on disk. In this particular case, it can even be faster than the raw dump. Also note that dump and load durations depend on the I/O speed of the underlying storage: for example, with SSD hard drives the LZ4 compression will be slightly slower than raw dump/load, whereas with spinning hard disk drives (HDD) or remote storage (NFS), LZ4 is faster in general.
LZMA and Zlib, even if always slower for dumping data, are quite fast when re-loading compressed data from disk.
plt.figure(2, figsize=(5, 4))
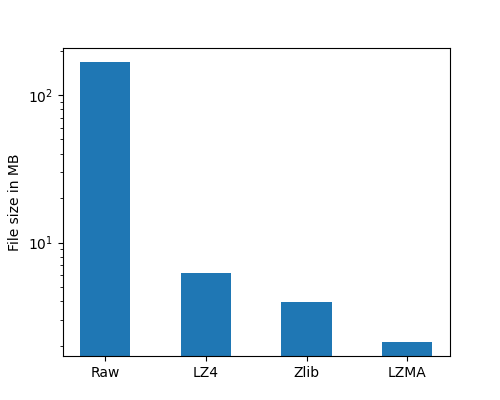
plt.bar(ind, file_sizes, width, log=True)
plt.ylabel("File size in MB")
plt.xticks(ind, ("Raw", "LZ4", "Zlib", "LZMA"))
([<matplotlib.axis.XTick object at 0x7502f7b2b110>, <matplotlib.axis.XTick object at 0x7502f7b2a850>, <matplotlib.axis.XTick object at 0x7502f7b5e210>, <matplotlib.axis.XTick object at 0x7502f7b5e990>], [Text(0, 0, 'Raw'), Text(1, 0, 'LZ4'), Text(2, 0, 'Zlib'), Text(3, 0, 'LZMA')])
Compressed data obviously takes a lot less space on disk than raw data. LZMA is the best compression method in terms of compression rate. Zlib also has a better compression rate than LZ4.
plt.show()
Clear the pickle file#
import os
os.remove(pickle_file)
Total running time of the script: (0 minutes 6.183 seconds)